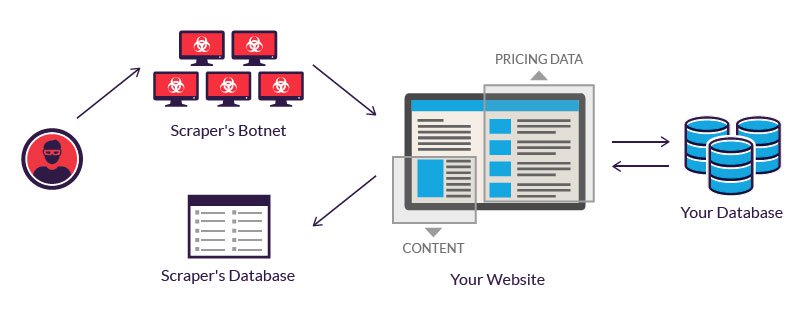
As well as it's a big distinction due to the fact that with scraping you typically understand the target sites, you might not understand the specific page Links, yet you know the domains at least. On the other hand, data crawling services are much more innovative as well as are designed to dig deep right into the web, regardless of what their goal could be. They are set to inspect all the feasible back links up until any kind of related info has been carefully examined. Data scraping is a wonderful technique when you wish to extract some info that is difficult to get to, such as product rates, for instance. Nonetheless, there are some minor downsides to this process.
- Apify's reputable and also effective system permits us to swiftly upgrade our content to remain in sync with the sanctuaries so users can discover their dogs fast.
- To see to it that we obtain the dynamically made HTML material of the web site, we pass the original source code dowloaded from the URL to our PhantomJS session first, as well as the use the rendered resource.
- Both languages are at the leading edge of development in internet scratching, boasting a huge choice of structures and libraries that provide devices to get over even the most intricate scraping situations.
You might be wondering why you need to actively add traffic jams to your tasks. This is because internet sites tend to have anti-crawler devices that can identify and also obstruct your demands if they all carry out at once. With node-crawler's rateLimit, time API Integrations spaces can be included between demands, to guarantee that they do not carry out at the very same time. Give your spiders an unfair benefit with Crawlee, our preferred collection for developing dependable scrapers in Node.js.
Make The Most Of Individual Representatives
Although they may appear to produce the exact same outcomes, the two techniques are rather different. Both of them are needed for the healing of information, yet the procedure included as well as the type of information requested differ in numerous ways. Information creeping digs deep right into the Internet to recover information.
What is the distinction between ditching as well as creeping?
Internet scratching aims to extract the information on websites, as well as internet creeping objectives to index as well as find websites. Web crawling includes following links completely based on links. In comparison, web scuffing suggests composing a program computer that can Data extraction services stealthily accumulate information from a number of sites.
You're not making 10s of countless demands to one site simultaneously; you're making 10 requests, waiting a couple of minutes, making another 10 demands, waiting a few minutes, and so forth. The searchUrl specifies where you ought to go to get search results if you append the subject you are trying to find. The resultListing defines the "box" that holds info about each outcome, and also the resultUrl defines the tag inside this box that will certainly give you the exact link for the outcome. The absoluteUrl residential or commercial property is a boolean that tells you whether these search results page are absolute or family member Links.
Utilizing Proxies For Internet Scraping
Proceeding with the previous instance, when you search for internet crawling vs. web scraping, the search engine crawls all of the net's website, including pictures and video clips. Search engines use internet spiders to creep all web pages by following the links embedded on those web pages. Internet crawlers uncover brand-new links to other Links as they crawl web pages and add these discovered web link to the crawl queue to creep next.
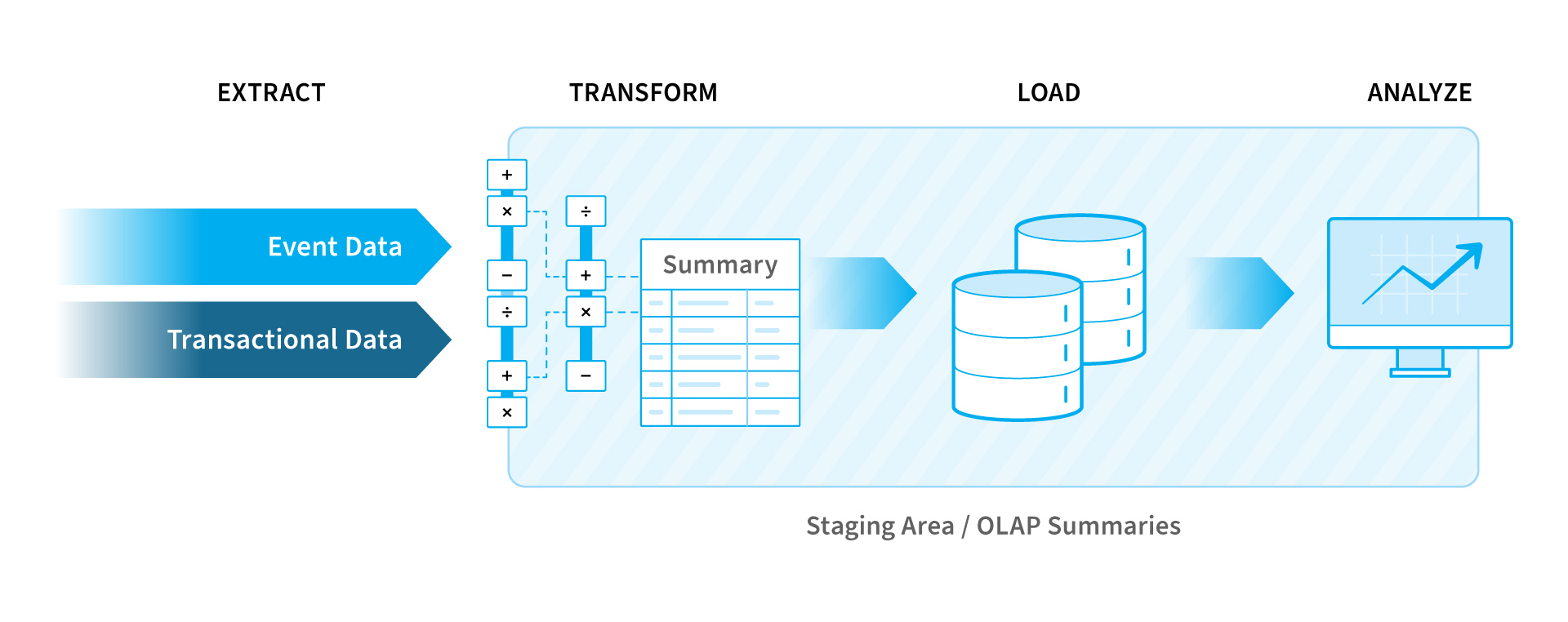
For this, we remove all href-attributes from a-elements suitable a specific CSS-class. To pick the best contents by means of XPATH-selectors, you require to examine the HTML-structure of your details web page. Modern browsers such as Firefox and also Chrome sustain you because job by a feature called "Check Component", offered via a right-click on the web page element. A practical method to download and also parse a webpage gives the function read_html which approves a link as a parameter. The feature downloads the web page and also interprets the html resource code as an HTML/ XML object. This tutorial covers just how to remove and refine message information from website or various other papers for later analysis.
Solutions For Organizations Are Required
Lovely Soup is a Python library made use of to extract HTML and XML aspects from a web page with just a few lines of code, making it the right selection to tackle simple jobs with speed. It is additionally relatively very easy to establish, find out, and also master, which makes it the optimal web scuffing device for beginners. Plus, you can automate your data removal and disappear making use of Octoparse's confidential proxy feature. That means your task will certainly revolve through tons of various IPs, which will stop you from being blocked by particular internet sites.
- Consequently, Python boasts some of one of the most popular web scratching collections and structures, such as BeautifulSoup, Selenium, Playwright, as well as Scrapy.
- Depend on smart IP address rotation with human-like web browser fingerprints.
- User agents enable the web server you wish to scratch to recognize which browser, operating system, or gadget you are making use of.
- Internet crawling is utilized for data removal as well as describes accumulating information from either the web or, in data creeping situations-- any kind of record, documents, etc.
- After the removal of the data, it is after that exchanged the format preferred by the author of the scrape robot.
Hyperlinks to a number of different sites come with the crawling cycle. Not only do they check out web API Integrations pages, however they additionally gather all the appropriate information and also index it while doing so. They additionally look for all web links to the related pages while doing so. Data scuffing and also data crawling are 2 terms that you frequently hear mutually.
Notification that we didn't need to fret about selecting the support tag a which contains the text. When we use.text is gets all message because element, and considering that "ABC News" is the only text, that's all we require to do. Bear in mind that using select or select_one will provide you the entire component with the tags included, so we need.text to provide us the text in between the tags. The outlet name is the message of a support tag that's nested inside a tag, which is a cell-- or table information tag.
https://maps.google.com/maps?saddr=340%20King%20St%20E%204th%20floor%2C%20Toronto%2C%20ON%20M5A%201K8%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
LogRocket tools your application to record standard performance timings such as page load time, time to very first byte, sluggish network requests, as well as also logs Redux, NgRx, as well as Vuex actions/state. Crawlee is written in Typescript, and it also makes use of Playwright and also Puppeteer. Due To The Fact That Dramatist and Puppeteer provide headless-browser capabilities, this indicates that you can scratch dynamic web pages. With rateLimit set to 2000, there will certainly be a two 2nd void in between demands. It allows us to remove components from HTML using the jQuery selector syntax($). OK, the Scrape wont run if you forget to add import scrapy to the first line of code.
Botanee to Double Revenue by 2026 as Chinese Skincare Giant ... - Yicai Global
Botanee to Double Revenue by 2026 as Chinese Skincare Giant ....
Posted: Thu, 13 Jul 2023 04:41:49 GMT [source]
What is the difference in between junking and creeping?
Web scuffing objectives to remove the data on website, as well as web creeping objectives to index as well as discover websites. Internet crawling includes complying with links permanently based upon hyperlinks. In comparison, web scraping indicates writing a program computer that can stealthily accumulate information from numerous sites.